Submitting complex metadata
So far, in the previous notebooks, we have learned how to submit and perform operations on simple samples, that is; samples that are isolated in the submission, and all its metadata is just a bunch of simple values.
However, life is not as simple; sometimes, you will want to (and will have to, as seen in the notebook about sample validation) attach some extra metadata to your samples, that being how it relates to other samples (is it a replicate? is it derived from another sample that you are submitting or has been submitted?) or that extra bit of metadata that makes your fields very demure (e.g. specifying a unit, or ❤️referencing an ontology value❤️)
On this notebook, we will focus on exactly that, with the following TOC:
Before you start
Submitting samples with relationships
All samples are being submitted for the first time
Some samples are already accessioned; some are not
All samples are accessioned but need to update relationships
How to improve your metadata via units and ontologies
Structured data
WTH is structured data
Structured data format and posting to sample
Posting a external URL (reference) to a sample
Validating against custom checklists
Before you start
Make sure you have biobroker >= 0.1.0
Before we start, we’re going to do the same we always do; however, a lot of features for this notebook need biobroker>=0.1.0 (The release where pydantic was introduced!) so… let’s start with that!
[2]:
%pip install biobroker --upgrade
%pip install datamodel-code-generator
Requirement already satisfied: biobroker in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (0.0.7)
Requirement already satisfied: numpy~=1.23.1 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from biobroker) (1.23.1)
Requirement already satisfied: openpyxl==3.1.2 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from biobroker) (3.1.2)
Requirement already satisfied: pandas~=2.0.3 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from biobroker) (2.0.3)
Requirement already satisfied: progressbar2~=4.4.2 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from biobroker) (4.4.2)
Requirement already satisfied: requests>=2.31.0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from biobroker) (2.31.0)
Requirement already satisfied: et-xmlfile in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from openpyxl==3.1.2->biobroker) (1.1.0)
Requirement already satisfied: python-dateutil>=2.8.2 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from pandas~=2.0.3->biobroker) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from pandas~=2.0.3->biobroker) (2024.2)
Requirement already satisfied: tzdata>=2022.1 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from pandas~=2.0.3->biobroker) (2024.2)
Requirement already satisfied: python-utils>=3.8.1 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from progressbar2~=4.4.2->biobroker) (3.9.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from requests>=2.31.0->biobroker) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from requests>=2.31.0->biobroker) (3.10)
Requirement already satisfied: urllib3<3,>=1.21.1 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from requests>=2.31.0->biobroker) (2.2.3)
Requirement already satisfied: certifi>=2017.4.17 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from requests>=2.31.0->biobroker) (2024.8.30)
Requirement already satisfied: six>=1.5 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from python-dateutil>=2.8.2->pandas~=2.0.3->biobroker) (1.16.0)
Requirement already satisfied: typing-extensions>3.10.0.2 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from python-utils>=3.8.1->progressbar2~=4.4.2->biobroker) (4.12.2)
Note: you may need to restart the kernel to use updated packages.
Requirement already satisfied: datamodel-code-generator in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (0.26.1)
Requirement already satisfied: argcomplete<4.0,>=1.10 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from datamodel-code-generator) (3.5.1)
Requirement already satisfied: black>=19.10b0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from datamodel-code-generator) (24.10.0)
Requirement already satisfied: genson<2.0,>=1.2.1 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from datamodel-code-generator) (1.3.0)
Requirement already satisfied: inflect<6.0,>=4.1.0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from datamodel-code-generator) (5.6.2)
Requirement already satisfied: isort<6.0,>=4.3.21 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from datamodel-code-generator) (5.13.2)
Requirement already satisfied: jinja2<4.0,>=2.10.1 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from datamodel-code-generator) (3.1.4)
Requirement already satisfied: packaging in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from datamodel-code-generator) (24.1)
Requirement already satisfied: pydantic!=2.4.0,<3.0,>=1.9.0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from pydantic[email]!=2.4.0,<3.0,>=1.9.0; python_version >= "3.10" and python_version < "3.11"->datamodel-code-generator) (2.9.2)
Requirement already satisfied: pyyaml>=6.0.1 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from datamodel-code-generator) (6.0.2)
Requirement already satisfied: toml<1.0.0,>=0.10.0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from datamodel-code-generator) (0.10.2)
Requirement already satisfied: click>=8.0.0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from black>=19.10b0->datamodel-code-generator) (8.1.7)
Requirement already satisfied: mypy-extensions>=0.4.3 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from black>=19.10b0->datamodel-code-generator) (1.0.0)
Requirement already satisfied: pathspec>=0.9.0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from black>=19.10b0->datamodel-code-generator) (0.12.1)
Requirement already satisfied: platformdirs>=2 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from black>=19.10b0->datamodel-code-generator) (4.3.6)
Requirement already satisfied: tomli>=1.1.0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from black>=19.10b0->datamodel-code-generator) (2.0.1)
Requirement already satisfied: typing-extensions>=4.0.1 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from black>=19.10b0->datamodel-code-generator) (4.12.2)
Requirement already satisfied: MarkupSafe>=2.0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from jinja2<4.0,>=2.10.1->datamodel-code-generator) (2.1.5)
Requirement already satisfied: annotated-types>=0.6.0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from pydantic!=2.4.0,<3.0,>=1.9.0->pydantic[email]!=2.4.0,<3.0,>=1.9.0; python_version >= "3.10" and python_version < "3.11"->datamodel-code-generator) (0.7.0)
Requirement already satisfied: pydantic-core==2.23.4 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from pydantic!=2.4.0,<3.0,>=1.9.0->pydantic[email]!=2.4.0,<3.0,>=1.9.0; python_version >= "3.10" and python_version < "3.11"->datamodel-code-generator) (2.23.4)
Requirement already satisfied: email-validator>=2.0.0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from pydantic[email]!=2.4.0,<3.0,>=1.9.0; python_version >= "3.10" and python_version < "3.11"->datamodel-code-generator) (2.2.0)
Requirement already satisfied: dnspython>=2.0.0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from email-validator>=2.0.0->pydantic[email]!=2.4.0,<3.0,>=1.9.0; python_version >= "3.10" and python_version < "3.11"->datamodel-code-generator) (2.7.0)
Requirement already satisfied: idna>=2.0.0 in /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages (from email-validator>=2.0.0->pydantic[email]!=2.4.0,<3.0,>=1.9.0; python_version >= "3.10" and python_version < "3.11"->datamodel-code-generator) (3.10)
Note: you may need to restart the kernel to use updated packages.
(Please make sure you re-start the kernel if you upgraded your version!)
Set-up and create samples
Once that’s set-up, we’re going to import everything and set up the basic metadata for 4 samples; the reason for setting up 4 samples this time will become apparent in the next sections
[2]:
## Import everything we need
from biobroker.authenticator import WebinAuthenticator # Biosamples uses the WebinAuthenticator
from biobroker.api import BsdApi # BioSamples Database (BSD) API
from biobroker.metadata_entity import Biosample # The metadata entity
from biobroker.input_processor import TsvInputProcessor # An input processor
from biobroker.output_processor import XlsxOutputProcessor # An output processor
import os
## Generate sample
sample_tsv = [
["name", "collected_at", "organism", "release"],
["Sample 1", "noon", "homo sapiens", "2024-01-07"],
["Sample 2", "noon", "homo sapiens", "2024-01-07"],
["Sample 3", "noon", "homo sapiens", "2024-01-07"],
["Sample 4", "noon", "homo sapiens", "2024-01-07"]
]
writable_sample = "\n".join(["\t".join(row) for row in sample_tsv])
with open("complex_sample_metadata.tsv", "w") as f:
f.write(writable_sample)
path = "complex_sample_metadata.tsv" # This is the file we created previously
## Set up the required entities
input_processor = TsvInputProcessor(input_data=path)
os.environ['API_ENVIRONMENT'] = "dev" # There are multiple ways to set up environment variables
username = "" # Your username goes here
password = "" # Your password goes here
authenticator = WebinAuthenticator(username=username, password=password)
api = BsdApi(authenticator=authenticator)
2024-10-14 12:23:56,713 - BsdApi - INFO - Set up BSD API successfully: using base uri 'https://wwwdev.ebi.ac.uk/biosamples/samples'
2024-10-14 12:24:04,626 - Biosample - ERROR - Metadata content has failed validation for 'Sample 1':
- characteristics: Missing mandatory field 'project name'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'collection date'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'geographic location (country and/or sea)'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'geographic location (latitude)'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'geographic location (longitude)'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'broad-scale environmental context'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'local environmental context'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'environmental medium'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'elevation'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'depth'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
2024-10-14 12:24:08,926 - Biosample - ERROR - Metadata content has failed validation for 'Sample 1':
- characteristics-->geographic location (country and/or sea)-->0-->text: Input should be 'Afghanistan', 'Albania', 'Algeria', 'American Samoa', 'Andorra', 'Angola', 'Anguilla', 'Antarctica', 'Antigua and Barbuda', 'Arctic Ocean', 'Argentina', 'Armenia', 'Aruba', 'Ashmore and Cartier Islands', 'Atlantic Ocean', 'Australia', 'Austria', 'Azerbaijan', 'Bahamas', 'Bahrain', 'Baker Island', 'Baltic Sea', 'Bangladesh', 'Barbados', 'Bassas da India', 'Belarus', 'Belgium', 'Belize', 'Benin', 'Bermuda', 'Bhutan', 'Bolivia', 'Borneo', 'Bosnia and Herzegovina', 'Botswana', 'Bouvet Island', 'Brazil', 'British Virgin Islands', 'Brunei', 'Bulgaria', 'Burkina Faso', 'Burundi', 'Cambodia', 'Cameroon', 'Canada', 'Cape Verde', 'Cayman Islands', 'Central African Republic', 'Chad', 'Chile', 'China', 'Christmas Island', 'Clipperton Island', 'Cocos Islands', 'Colombia', 'Comoros', 'Cook Islands', 'Coral Sea Islands', 'Costa Rica', "Cote d'Ivoire", 'Croatia', 'Cuba', 'Curacao', 'Cyprus', 'Czechia', 'Democratic Republic of the Congo', 'Denmark', 'Djibouti', 'Dominica', 'Dominican Republic', 'East Timor', 'Ecuador', 'Egypt', 'El Salvador', 'Equatorial Guinea', 'Eritrea', 'Estonia', 'Ethiopia', 'Europa Island', 'Falkland Islands (Islas Malvinas)', 'Faroe Islands', 'Fiji', 'Finland', 'France', 'French Guiana', 'French Polynesia', 'French Southern and Antarctic Lands', 'Gabon', 'Gambia', 'Gaza Strip', 'Georgia', 'Germany', 'Ghana', 'Gibraltar', 'Glorioso Islands', 'Greece', 'Greenland', 'Grenada', 'Guadeloupe', 'Guam', 'Guatemala', 'Guernsey', 'Guinea', 'Guinea-Bissau', 'Guyana', 'Haiti', 'Heard Island and McDonald Islands', 'Honduras', 'Hong Kong', 'Howland Island', 'Hungary', 'Iceland', 'India', 'Indian Ocean', 'Indonesia', 'Iran', 'Iraq', 'Ireland', 'Isle of Man', 'Israel', 'Italy', 'Jamaica', 'Jan Mayen', 'Japan', 'Jarvis Island', 'Jersey', 'Johnston Atoll', 'Jordan', 'Juan de Nova Island', 'Kazakhstan', 'Kenya', 'Kerguelen Archipelago', 'Kingman Reef', 'Kiribati', 'Kosovo', 'Kuwait', 'Kyrgyzstan', 'Laos', 'Latvia', 'Lebanon', 'Lesotho', 'Liberia', 'Libya', 'Liechtenstein', 'Lithuania', 'Luxembourg', 'Macau', 'Macedonia', 'Madagascar', 'Malawi', 'Malaysia', 'Maldives', 'Mali', 'Malta', 'Marshall Islands', 'Martinique', 'Mauritania', 'Mauritius', 'Mayotte', 'Mediterranean Sea', 'Mexico', 'Micronesia', 'Midway Islands', 'Moldova', 'Monaco', 'Mongolia', 'Montenegro', 'Montserrat', 'Morocco', 'Mozambique', 'Myanmar', 'Namibia', 'Nauru', 'Navassa Island', 'Nepal', 'Netherlands', 'New Caledonia', 'New Zealand', 'Nicaragua', 'Niger', 'Nigeria', 'Niue', 'Norfolk Island', 'North Korea', 'North Sea', 'Northern Mariana Islands', 'Norway', 'Oman', 'Pacific Ocean', 'Pakistan', 'Palau', 'Palmyra Atoll', 'Panama', 'Papua New Guinea', 'Paracel Islands', 'Paraguay', 'Peru', 'Philippines', 'Pitcairn Islands', 'Poland', 'Portugal', 'Puerto Rico', 'Qatar', 'Republic of the Congo', 'Reunion', 'Romania', 'Ross Sea', 'Russia', 'Rwanda', 'Saint Helena', 'Saint Kitts and Nevis', 'Saint Lucia', 'Saint Pierre and Miquelon', 'Saint Vincent and the Grenadines', 'Samoa', 'San Marino', 'Sao Tome and Principe', 'Saudi Arabia', 'Senegal', 'Serbia', 'Seychelles', 'Sierra Leone', 'Singapore', 'Sint Maarten', 'Slovakia', 'Slovenia', 'Solomon Islands', 'Somalia', 'South Africa', 'South Georgia and the South Sandwich Islands', 'South Korea', 'Southern Ocean', 'Spain', 'Spratly Islands', 'Sri Lanka', 'Sudan', 'Suriname', 'Svalbard', 'Swaziland', 'Sweden', 'Switzerland', 'Syria', 'Taiwan', 'Tajikistan', 'Tanzania', 'Tasman Sea', 'Thailand', 'Togo', 'Tokelau', 'Tonga', 'Trinidad and Tobago', 'Tromelin Island', 'Tunisia', 'Turkey', 'Turkmenistan', 'Turks and Caicos Islands', 'Tuvalu', 'USA', 'Uganda', 'Ukraine', 'United Arab Emirates', 'United Kingdom', 'Uruguay', 'Uzbekistan', 'Vanuatu', 'Venezuela', 'Viet Nam', 'Virgin Islands', 'Wake Island', 'Wallis and Futuna', 'West Bank', 'Western Sahara', 'Yemen', 'Zambia', 'Zimbabwe', 'missing: control sample', 'missing: data agreement established pre-2023', 'missing: endangered species', 'missing: human-identifiable', 'missing: lab stock', 'missing: sample group', 'missing: synthetic construct', 'missing: third party data', 'not applicable', 'not collected', 'not provided' or 'restricted access'. Provided value: 'Mushroom kingdom'
- characteristics-->geographic location (latitude)-->0-->text: Input should be a valid string. Provided value: '1.2234'
- characteristics-->geographic location (longitude)-->0-->text: Input should be a valid string. Provided value: '7.21'
- characteristics: Missing mandatory field 'elevation'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'Homo sapiens'}], 'project name': [{'text': 'Your fake project'}], 'collection date': [{'text': '2024-09-01'}], 'geographic location (country and/or sea)': [{'text': 'Mushroom kingdom'}], 'geographic location (latitude)': [{'text': 1.2234}], 'geographic location (longitude)': [{'text': 7.21}], 'broad-scale environmental context': [{'text': 'United Kingdom weather'}], 'local environmental context': [{'text': 'Mostly rainy'}], 'environmental medium': [{'text': 'Please read my plant'}]}'
- characteristics: Missing mandatory field 'depth'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'Homo sapiens'}], 'project name': [{'text': 'Your fake project'}], 'collection date': [{'text': '2024-09-01'}], 'geographic location (country and/or sea)': [{'text': 'Mushroom kingdom'}], 'geographic location (latitude)': [{'text': 1.2234}], 'geographic location (longitude)': [{'text': 7.21}], 'broad-scale environmental context': [{'text': 'United Kingdom weather'}], 'local environmental context': [{'text': 'Mostly rainy'}], 'environmental medium': [{'text': 'Please read my plant'}]}'
2024-10-14 12:24:29,603 - BsdApi - ERROR - Found following errors in sample validation:
- geographic location (latitude)/0.unit: should have required property 'unit'
- geographic location (longitude)/0.unit: should have required property 'unit'
- elevation/0.unit: should have required property 'unit'
- depth/0.unit: should have required property 'unit')
Submitting samples with relationships
Depending on your metadata model, you may want to create entries in BioSamples that are related to each other; Maybe instead of repeating the important metadata from a parent sample (e.g. a cell line), you want to capture that metadata in its own entry and link the library preparations as samples derived from that one.
Biosamples has got you covered! (And biobroker too). In BioSamples, you can link different samples that you have submitted using the attributes derived_from, same_as, has_member and child_of. You can find more information on these relationship types in https://www.ebi.ac.uk/biosamples/docs/guides/relationships. An important thing to remember about relationships is that they are bi-directional: That means, if you specify a type of relationship on sample A towards sample B,
the inverse (or equal, in the case of same_as) will automatically apply on the sample
biobroker processes these relationships by reserving the name of the relationships as keywords for the metadata entry. What that means, in practice, is: to indicate that samples are related to each on the input metadata, you just need to add a column/field with the name of the keyword.
Let’s go through a set of use cases so it becomes clearer:
All samples are being submitted for the first time
Alright! So, let’s say we have the four samples we have defined before. We know they are related in the following way:
graph LR;
A[Sample 1]
B[Sample 2]
C[Sample 3]
D[Sample 4]
B-->|derived_from|A
C-->|derived_from|A
D-->|derived_from|A
B-->|same_as|C
B-->|same_as|D
C-->|same_as|D
Looks complicated, but all I want to represent is: All samples are derived from Sample 1, and the derived samples are all replicates.
In this specific case, we have 4 samples that have not yet been submitted; and biosamples only accepts sample accessions as an input for the relationships. How are we going to do it?
The short and sad answer is: You need to submit the samples and then update them with the relationships.
The cooler answer is that I got this covered in biobroker! On the BsdApi object there is a keyword argument you can pass to the submit function, process_relationships, that when set to True, will do the trick for you so you just need to worry.
But forget about all this theory and let’s go into practice. The first thing we need to do is to define this relationships. You may have noticed we didn’t process the samples before; that is because I want a clean slate for each of the examples, so we will start each example by loading the samples.
[9]:
samples_relationships_non_accessioned = input_processor.process(Biosample)
Now that we have the samples loaded in, let’s add the relationships. Since they are not accessioned, we are going to add the relationships using the name of the samples and the reserved keywords we talked about before.
Please note: This is much easier and intuitive to do on the input metadata (excel, tsv etc) directly and load it with an input processor rather doing it here, but I am not going to create a file just for these samples. Just rembember that, index-wise, sample correspond to their index + 1 (e.g. index 0 of the samples is Sample 1)
[10]:
## All samples are derived from Sample 1
samples_relationships_non_accessioned[1]['derived_from'] = "Sample 1"
samples_relationships_non_accessioned[2]['derived_from'] = "Sample 1"
samples_relationships_non_accessioned[3]['derived_from'] = "Sample 1"
## Samples 2, 3 and 4 are replicates.
samples_relationships_non_accessioned[1]['same_as'] = "Sample 3||Sample 4"
samples_relationships_non_accessioned[2]['same_as'] = "Sample 4"
Now we have the metadata in order to start submitting and processing those relationships!
One very important thing to notice is how I used the double pipes to indicate more than one relationship. You may need to adjust the delimiter for the different entities, depending on how you set the Biosample. The default delimiter for the entity is a double pipe (||). We will use this for multiple relationships, multiple urls, etc. It’s not a perfect solution but it’s a much easier to handle solution rather than starting to create columns with programmatic names and parsing that as
arrays!
We will now submit the samples, as usual, with a slight change: we are going to provide with the process_relationships keyword. What this will do, in short, is to submit the samples as is, process the relationships afterwards, and update them.
[11]:
submitted_samples = api.submit(samples_relationships_non_accessioned, process_relationships=True)
Let’s see what our submitted samples look like!
[13]:
print(f"https://wwwdev.ebi.ac.uk/biosamples/samples/{submitted_samples[0].accession}")
https://wwwdev.ebi.ac.uk/biosamples/samples/SAMEA131399004
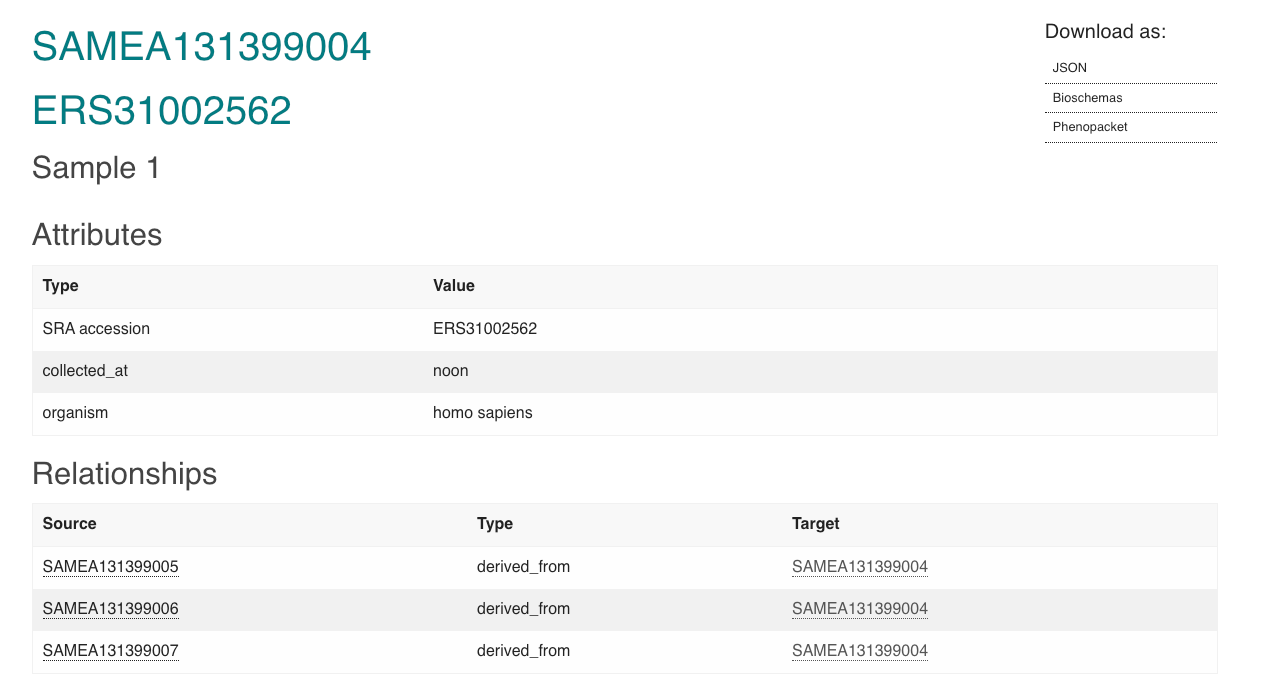
As we can see… The relationships have gone through! Wooho! Now we have all of our samples linked together. This is just the example for the parent sample, but if you go to the link, you will see that the relationships are also defined for the child samples.
Mixing accessioned and non-accessioned samples
The previous example was very simple; in that case, all of our samples were not submitted, so we could define all the relationships in our input and let BsdApi.submit() handle the process. However, that is not going to be always the case; sometimes you will have a parent sample that you have already registered, and child samples that you produced (replicates) that need to be now registered after you’ve finished your experiments.
For that, we are going to use the same set of samples as before, with the new relationships; just this time, we are going to submit the parent sample first.
[2]:
samples_relationships_mixed_accessioned = input_processor.process(Biosample)
parent_sample = [samples_relationships_mixed_accessioned[0]]
child_samples = samples_relationships_mixed_accessioned[1:]
parent_sample_submitted = api.submit(parent_sample)
Once the parent sample is submitted, we are going to indicate the relationship in the child samples by using the accession
[3]:
## All samples are derived from Sample 1
child_samples[0]['derived_from'] = parent_sample_submitted[0].accession
child_samples[1]['derived_from'] = parent_sample_submitted[0].accession
child_samples[2]['derived_from'] = parent_sample_submitted[0].accession
## Samples 2, 3 and 4 are replicates.
child_samples[0]['same_as'] = "Sample 3||Sample 4"
child_samples[1]['same_as'] = "Sample 4"
Now that we have our child samples set up, let’s try to submit them!
[4]:
submitted_samples_mixed_accessioning = api.submit(child_samples, process_relationships=True)
[5]:
print(f"https://wwwdev.ebi.ac.uk/biosamples/samples/{submitted_samples_mixed_accessioning[0].accession}")
https://wwwdev.ebi.ac.uk/biosamples/samples/SAMEA131399017
And, as we can see, the samples are submitted with the relationships attached! Isn’t that neat?
Updating relationships
Updating the relationships for already accesioned samples is pretty straight-forward; for this, you just need to retrieve the samples (You can use multiple methods for that - You can refer to notebook 4 for more information).
Once you’ve got the samples, you just need to update the metadata to include the relationship; for this, you can either: * Add the value for each of the samples retrieved in your script and update them using BsdApi.update() * Output the samples to a more user-friendly format (Xlsx, tsv) modify them, load them back and update them using BsdApi.update()
The metadata entities automatically recognise that the origin sample is accessioned, so when you add the relationship, it will be added to the proper metadata and you don’t need to use the process_relationships function.
There is a third, more complicated option, which is to specify them somewhat manually; there is a function, `add_relationship <https://biobroker.readthedocs.io/en/latest/biobroker.metadata_entity.html#biobroker.metadata_entity.Biosample.add_relationship>`__ for which you can specify the relationship manually, but… I don’t really think it’s worth it. I made it really simple for the user!
Structured data
What in the world is structured data
There is another layer of information that you can add to a sample; when you’re recording metadata for a sample, you can sometimes generate a table of information (e.g. an Antibiogram). You could attach this information to the sample in a very weird and complicated way; however, biosamples provides with the ability to provide tables with tagged information and a title, and they call it structured data. For a couple examples of structured data, you can look at this sample in production:
https://www.ebi.ac.uk/biosamples/samples/SAMEA112948612 or look at the documentation examples
Structured data format
Let’s do a simple task of creating some very simple structured data. Let’s say that, for our case, we have realised an assay on the sample, that returns a very complex 2x2 table (scary)
For this, let’s start by loading up the samples and getting just the first one for this task and define the table!
[6]:
# Get the samples
samples_st = input_processor.process(Biosample)
# Choose just the first sample and submit it
sample_example = [samples_st[0]]
sample_example_submitted = api.submit(sample_example)
data_table = [[1, 34.5],
[2, 33.7]]
Now that we have all the necessary things set up, let’s start structuring the table in the necessary format. In the code, this will all be one step, but take a look at the comments! I will be commenting each line that needs clarification.
[11]:
structured_data = { # Please note, the structured data is submitted as a dictionary!
'accession': sample_example_submitted[0].accession, # Accession must be provided with the structured data
'data': [ # This array is for all the different, unrelated tables you want to submit. Here, we only have one table, so the array will have lenght 1
{
'webinSubmissionAccountId': 'Webin-64342', # For some goddam reason they need your webin account there
'type': 'MYAWESOMEASSAY', # This is the name of the table; usually, the name of the assay
# Note here: You can specify a `schema` property to validate the content of your table. Not going to do it
'content': [ # This is the actual data table! wooho! each of the elements of the aray is a dictionary with the values associated to a field name
{ # We have 2 rows, so we expect 2 dictionaries
'time point': { # Each field-value is defined as in the usual for BSD: 'value' is needed (instead of 'text'), and you can add tags
'value': 1,
'unit': 'hour'
},
'luminosity': {
'value': 34.5
}
},
{
'time point': {
'value': 2,
'unit': 'hour'
},
'luminosity': {
'value': 33.7
}
}
]
}
]
}
# You could also generate the content automatically by iterating the data table. Feel free to use your preferred method!
content = [{'timepoint': {'value': row[0], 'unit': 'hour'}, 'luminosity': {'value': row[1]}} for row in data_table]
structured_data['data'][0]['content'] = content
# Let's take a look at the structured data!
print(structured_data)
{'accession': 'SAMEA131399379', 'data': [{'webinSubmissionAccountId': 'Webin-64342', 'type': 'MYAWESOMEASSAY', 'content': [{'timepoint': {'value': 1, 'unit': 'hour'}, 'luminosity': {'value': 34.5}}, {'timepoint': {'value': 2, 'unit': 'hour'}, 'luminosity': {'value': 33.7}}]}]}
[15]:
response = api.authenticator.post(url=f"{api.structured_data_endpoint}/{structured_data['accession']}", payload=structured_data)
print(response.text)
{
"accession" : "SAMEA131399379",
"create" : "2024-10-06T19:18:11.785Z",
"update" : "2024-10-06T19:18:11.786Z",
"data" : [ {
"domain" : null,
"webinSubmissionAccountId" : "Webin-64342",
"type" : "MYAWESOMEASSAY",
"schema" : null,
"content" : [ {
"timepoint" : {
"value" : "1",
"iri" : null
},
"luminosity" : {
"value" : "34.5",
"iri" : null
}
}, {
"timepoint" : {
"value" : "2",
"iri" : null
},
"luminosity" : {
"value" : "33.7",
"iri" : null
}
} ]
} ]
}
(Another error I found while writing these examples - The returned response is the structured data, not the sample - will fix in 0.0.7 and use the proper function to do this)
As you can see, it has returned the data created. Let’s take a look at the BioSamples entry!
https://wwwdev.ebi.ac.uk/biosamples/samples/SAMEA131399379
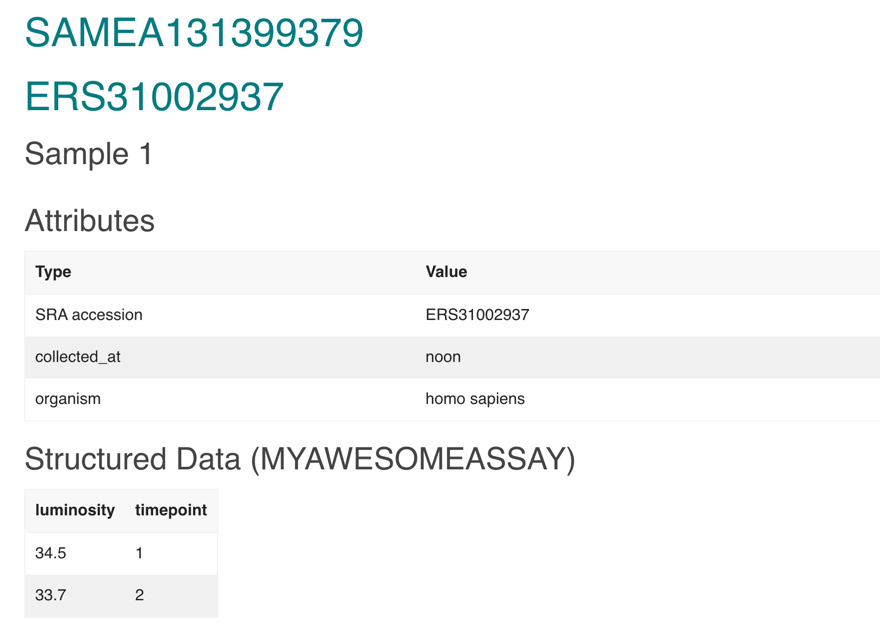
## Posting an external reference (URI)
The last, and probably easiest, is adding external references. In BSD, external references are used to link data that could not be hosted in BSD to the entry, to have a single source of truth for all the data related to a sample.
One example of this are the ENA links to the Genomics/Transcriptomics data - But in any case, these links are generated automatically by BioSamples if you remember to use your sample accession in your ENA submission :)
Here I will only say that, similarly to the relationships, URLs can be added with the function add_external_reference() on the samples.
Validating against a custom checklist
For this one, I’ve left the least user-friendly capability of the biobroker library for last: The ability to validate your own metadata via the use of the Pydantic library.
For a thorough explanation of what pydantic is, please consult their webpage. For us, in short, is a way to validate the metadata of our samples via the use of python classes. Sounds complicated, but don’t worry, I will provide with 2 examples:
Using an already existing BioSamples checklist and transforming it to a pydantic model
Modifying an existing pydantic model to satisfy your validation rules
Please take into account that pydantic offers a HUGE range of validation options: What biobroker does with that is, basically, offer a validate() method. This method: - Takes in a subclass of a pydantic BaseModel - Loads the data in .entity to that BaseModel. During instantiation, pydantic deals with validation. - If errors: Parse error returned by Pydantic and offer it to the user. - If no error: Dump the resulting JSON back to .entity
(Why dump the resulting JSON back to .entity if we’re just validating, you ask? Well, we’re not JUST validating: pydantic also offers a bit of data formatting so, if e.g. I am expecting a string, and someone inputs a “1”, it will transform the 1 value to "1". Cool, right?)
So, basically, in this section you will learn how to use your own checklists for validation; this may serve the purpose of pre-submission validation against a checklist, or if you are using a custom checklist (e.g. Want to use ERC000022 to validate against your checklist, but you want your consortia to specify a time point and you want to stablish rules against that specific field)
Validate your samples against an existing checklist
Let’s say we want to pre-validate our samples against ERC000022. The first step to take is to download the checklist in a JSON schema format; For that, Biosamples stores the schemas in a public schema store. The URL to the ERC000022 checlist is: https://www.ebi.ac.uk/biosamples/schema/store/registry/schemas/ERC000022
The next step is to convert this checklist to a pydantic-compatible model; for that, thankfully, there are a lot of tools. For this one, we will use the recommended tool datamodel code generator. Please make sure you follow their installation instructions before continuing!
[2]:
!datamodel-codegen --url "https://www.ebi.ac.uk/biosamples/schema/store/registry/schemas/ERC000022" --input-file-type jsonschema --output-model-type pydantic_v2.BaseModel --output ERC000022.py
[3]:
from ERC000022 import GscMixsSoil # We load the main class - This is the root of the schema!
Alrighty! now we have loaded the model. Let’s prepare our sample to be validated against this checklist!
[4]:
samples_checklist_validation = input_processor.process(Biosample)
sample_checklist_validation = samples_checklist_validation[0] # Let's just take 1 sample for the example
sample_checklist_validation.validate(GscMixsSoil) # We pass the model to validate against the metadata
---------------------------------------------------------------------------
EntityValidationError Traceback (most recent call last)
Cell In[4], line 4
1 samples_checklist_validation = input_processor.process(Biosample)
2 sample_checklist_validation = samples_checklist_validation[0] # Let's just take 1 sample for the example
----> 4 sample_checklist_validation.validate(GscMixsSoil) # We pass the model to validate against the metadata
File ~/PycharmProjects/biobroker/biobroker/metadata_entity/metadata_entity.py:75, in GenericEntity.validate(self, data_model)
73 self.entity = data_model(**self.entity).model_dump(exclude_unset=True, by_alias=True)
74 except pydantic_core.ValidationError as pydantic_error:
---> 75 raise EntityValidationError(self.logger, entity_id=self.id, errors=pydantic_error.errors()) from None
EntityValidationError: Metadata content has failed validation for 'Sample 1':
- characteristics: Missing mandatory field 'project name'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'collection date'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'geographic location (country and/or sea)'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'geographic location (latitude)'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'geographic location (longitude)'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'broad-scale environmental context'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'local environmental context'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'environmental medium'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'elevation'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
- characteristics: Missing mandatory field 'depth'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'homo sapiens'}]}'
Similar to what we did in notebook 2, let’s correct the missing fields!
[5]:
sample_checklist_validation['project name'] = "Your fake project"
sample_checklist_validation['organism'] = "Homo sapiens"
sample_checklist_validation['collection date'] = "2024-09-01"
sample_checklist_validation['geographic location (country and/or sea)'] = "Mushroom kingdom"
sample_checklist_validation['geographic location (latitude)'] = 1.2234
sample_checklist_validation['geographic location (longitude)'] = 7.21
sample_checklist_validation['broad-scale environmental context'] = "United Kingdom weather"
sample_checklist_validation['local environmental context'] = "Mostly rainy"
sample_checklist_validation['environmental medium'] = "Please read my plant"
And validate again!
[6]:
sample_checklist_validation.validate(GscMixsSoil)
---------------------------------------------------------------------------
EntityValidationError Traceback (most recent call last)
Cell In[6], line 1
----> 1 sample_checklist_validation.validate(GscMixsSoil)
File ~/PycharmProjects/biobroker/biobroker/metadata_entity/metadata_entity.py:75, in GenericEntity.validate(self, data_model)
73 self.entity = data_model(**self.entity).model_dump(exclude_unset=True, by_alias=True)
74 except pydantic_core.ValidationError as pydantic_error:
---> 75 raise EntityValidationError(self.logger, entity_id=self.id, errors=pydantic_error.errors()) from None
EntityValidationError: Metadata content has failed validation for 'Sample 1':
- characteristics-->geographic location (country and/or sea)-->0-->text: Input should be 'Afghanistan', 'Albania', 'Algeria', 'American Samoa', 'Andorra', 'Angola', 'Anguilla', 'Antarctica', 'Antigua and Barbuda', 'Arctic Ocean', 'Argentina', 'Armenia', 'Aruba', 'Ashmore and Cartier Islands', 'Atlantic Ocean', 'Australia', 'Austria', 'Azerbaijan', 'Bahamas', 'Bahrain', 'Baker Island', 'Baltic Sea', 'Bangladesh', 'Barbados', 'Bassas da India', 'Belarus', 'Belgium', 'Belize', 'Benin', 'Bermuda', 'Bhutan', 'Bolivia', 'Borneo', 'Bosnia and Herzegovina', 'Botswana', 'Bouvet Island', 'Brazil', 'British Virgin Islands', 'Brunei', 'Bulgaria', 'Burkina Faso', 'Burundi', 'Cambodia', 'Cameroon', 'Canada', 'Cape Verde', 'Cayman Islands', 'Central African Republic', 'Chad', 'Chile', 'China', 'Christmas Island', 'Clipperton Island', 'Cocos Islands', 'Colombia', 'Comoros', 'Cook Islands', 'Coral Sea Islands', 'Costa Rica', "Cote d'Ivoire", 'Croatia', 'Cuba', 'Curacao', 'Cyprus', 'Czechia', 'Democratic Republic of the Congo', 'Denmark', 'Djibouti', 'Dominica', 'Dominican Republic', 'East Timor', 'Ecuador', 'Egypt', 'El Salvador', 'Equatorial Guinea', 'Eritrea', 'Estonia', 'Ethiopia', 'Europa Island', 'Falkland Islands (Islas Malvinas)', 'Faroe Islands', 'Fiji', 'Finland', 'France', 'French Guiana', 'French Polynesia', 'French Southern and Antarctic Lands', 'Gabon', 'Gambia', 'Gaza Strip', 'Georgia', 'Germany', 'Ghana', 'Gibraltar', 'Glorioso Islands', 'Greece', 'Greenland', 'Grenada', 'Guadeloupe', 'Guam', 'Guatemala', 'Guernsey', 'Guinea', 'Guinea-Bissau', 'Guyana', 'Haiti', 'Heard Island and McDonald Islands', 'Honduras', 'Hong Kong', 'Howland Island', 'Hungary', 'Iceland', 'India', 'Indian Ocean', 'Indonesia', 'Iran', 'Iraq', 'Ireland', 'Isle of Man', 'Israel', 'Italy', 'Jamaica', 'Jan Mayen', 'Japan', 'Jarvis Island', 'Jersey', 'Johnston Atoll', 'Jordan', 'Juan de Nova Island', 'Kazakhstan', 'Kenya', 'Kerguelen Archipelago', 'Kingman Reef', 'Kiribati', 'Kosovo', 'Kuwait', 'Kyrgyzstan', 'Laos', 'Latvia', 'Lebanon', 'Lesotho', 'Liberia', 'Libya', 'Liechtenstein', 'Lithuania', 'Luxembourg', 'Macau', 'Macedonia', 'Madagascar', 'Malawi', 'Malaysia', 'Maldives', 'Mali', 'Malta', 'Marshall Islands', 'Martinique', 'Mauritania', 'Mauritius', 'Mayotte', 'Mediterranean Sea', 'Mexico', 'Micronesia', 'Midway Islands', 'Moldova', 'Monaco', 'Mongolia', 'Montenegro', 'Montserrat', 'Morocco', 'Mozambique', 'Myanmar', 'Namibia', 'Nauru', 'Navassa Island', 'Nepal', 'Netherlands', 'New Caledonia', 'New Zealand', 'Nicaragua', 'Niger', 'Nigeria', 'Niue', 'Norfolk Island', 'North Korea', 'North Sea', 'Northern Mariana Islands', 'Norway', 'Oman', 'Pacific Ocean', 'Pakistan', 'Palau', 'Palmyra Atoll', 'Panama', 'Papua New Guinea', 'Paracel Islands', 'Paraguay', 'Peru', 'Philippines', 'Pitcairn Islands', 'Poland', 'Portugal', 'Puerto Rico', 'Qatar', 'Republic of the Congo', 'Reunion', 'Romania', 'Ross Sea', 'Russia', 'Rwanda', 'Saint Helena', 'Saint Kitts and Nevis', 'Saint Lucia', 'Saint Pierre and Miquelon', 'Saint Vincent and the Grenadines', 'Samoa', 'San Marino', 'Sao Tome and Principe', 'Saudi Arabia', 'Senegal', 'Serbia', 'Seychelles', 'Sierra Leone', 'Singapore', 'Sint Maarten', 'Slovakia', 'Slovenia', 'Solomon Islands', 'Somalia', 'South Africa', 'South Georgia and the South Sandwich Islands', 'South Korea', 'Southern Ocean', 'Spain', 'Spratly Islands', 'Sri Lanka', 'Sudan', 'Suriname', 'Svalbard', 'Swaziland', 'Sweden', 'Switzerland', 'Syria', 'Taiwan', 'Tajikistan', 'Tanzania', 'Tasman Sea', 'Thailand', 'Togo', 'Tokelau', 'Tonga', 'Trinidad and Tobago', 'Tromelin Island', 'Tunisia', 'Turkey', 'Turkmenistan', 'Turks and Caicos Islands', 'Tuvalu', 'USA', 'Uganda', 'Ukraine', 'United Arab Emirates', 'United Kingdom', 'Uruguay', 'Uzbekistan', 'Vanuatu', 'Venezuela', 'Viet Nam', 'Virgin Islands', 'Wake Island', 'Wallis and Futuna', 'West Bank', 'Western Sahara', 'Yemen', 'Zambia', 'Zimbabwe', 'missing: control sample', 'missing: data agreement established pre-2023', 'missing: endangered species', 'missing: human-identifiable', 'missing: lab stock', 'missing: sample group', 'missing: synthetic construct', 'missing: third party data', 'not applicable', 'not collected', 'not provided' or 'restricted access'. Provided value: 'Mushroom kingdom'
- characteristics-->geographic location (latitude)-->0-->text: Input should be a valid string. Provided value: '1.2234'
- characteristics-->geographic location (longitude)-->0-->text: Input should be a valid string. Provided value: '7.21'
- characteristics: Missing mandatory field 'elevation'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'Homo sapiens'}], 'project name': [{'text': 'Your fake project'}], 'collection date': [{'text': '2024-09-01'}], 'geographic location (country and/or sea)': [{'text': 'Mushroom kingdom'}], 'geographic location (latitude)': [{'text': 1.2234}], 'geographic location (longitude)': [{'text': 7.21}], 'broad-scale environmental context': [{'text': 'United Kingdom weather'}], 'local environmental context': [{'text': 'Mostly rainy'}], 'environmental medium': [{'text': 'Please read my plant'}]}'
- characteristics: Missing mandatory field 'depth'. Provided value: '{'collected_at': [{'text': 'noon'}], 'organism': [{'text': 'Homo sapiens'}], 'project name': [{'text': 'Your fake project'}], 'collection date': [{'text': '2024-09-01'}], 'geographic location (country and/or sea)': [{'text': 'Mushroom kingdom'}], 'geographic location (latitude)': [{'text': 1.2234}], 'geographic location (longitude)': [{'text': 7.21}], 'broad-scale environmental context': [{'text': 'United Kingdom weather'}], 'local environmental context': [{'text': 'Mostly rainy'}], 'environmental medium': [{'text': 'Please read my plant'}]}'
As we can see, it’s complaining about a series of value errors. These value errors differ a bit from the value errors we saw in notebook 2: that is due to the automatically-generated model being a bit more constrained that the Biosamples checks. We could modify the model slightly to make it work better, but for the sake of the notebook, let’s just input the values as expected:
[7]:
sample_checklist_validation['geographic location (country and/or sea)'] = "Mediterranean Sea"
sample_checklist_validation['geographic location (latitude)'] = str(sample_checklist_validation['geographic location (latitude)']['text'])
sample_checklist_validation['geographic location (longitude)'] = str(sample_checklist_validation['geographic location (latitude)']['text'])
sample_checklist_validation['elevation'] = "1"
sample_checklist_validation['depth'] = "1"
sample_checklist_validation.validate(GscMixsSoil)
And now it has validated! Hoorray! It should be ready to submit, so let’s just try that
[9]:
sample_checklist_validation['checklist'] = 'ERC000022' # We still need to tell BSD that we want to validate our samples!
submitted_checklist_sample = api.submit([sample_checklist_validation])
print(f"{api.base_uri}/{submitted_checklist_sample.accession}")
---------------------------------------------------------------------------
BiosamplesValidationError Traceback (most recent call last)
Cell In[9], line 2
1 sample_checklist_validation['checklist'] = 'ERC000022' # We still need to tell BSD that we want to validate our samples!
----> 2 submitted_checklist_sample = api.submit([sample_checklist_validation])
3 print(f"{api.base_uri}/{submitted_checklist_sample.accession}")
File ~/PycharmProjects/biobroker/biobroker/api/api.py:51, in GenericApi.submit(self, entities, **kwargs)
49 return self._submit_multiple(entities, kwargs)
50 else:
---> 51 return [self._submit(entities[0], kwargs)]
File ~/PycharmProjects/biobroker/biobroker/api/api.py:172, in BsdApi._submit(self, entity, kwargs)
170 r = self.authenticator.post(submit_url, payload=entity.entity)
171 if r.status_code > 300:
--> 172 self._submit_errors(r)
173 return Biosample(r.json())
File ~/PycharmProjects/biobroker/biobroker/api/api.py:390, in BsdApi._submit_errors(self, response)
388 if response.status_code == 400:
389 if "dataPath" in response.text:
--> 390 raise BiosamplesValidationError(response.text, self.logger)
391 else:
392 raise BiosamplesNoErrorMessageError(response.status_code, self.logger)
BiosamplesValidationError: Found following errors in sample validation:
- geographic location (latitude)/0.unit: should have required property 'unit'
- geographic location (longitude)/0.unit: should have required property 'unit'
- elevation/0.unit: should have required property 'unit'
- depth/0.unit: should have required property 'unit')
[8]:
print(sample_checklist_validation.entity)
{'characteristics': {'project name': [{'text': 'Your fake project'}], 'collection date': [{'text': '2024-09-01'}], 'geographic location (country and/or sea)': [{'text': <Text5.Mediterranean_Sea: 'Mediterranean Sea'>}], 'geographic location (latitude)': [{'text': '1.2234'}], 'geographic location (longitude)': [{'text': '1.2234'}], 'broad-scale environmental context': [{'text': 'United Kingdom weather'}], 'local environmental context': [{'text': 'Mostly rainy'}], 'environmental medium': [{'text': 'Please read my plant'}], 'elevation': [{'text': '1'}], 'depth': [{'text': '1'}]}, 'name': 'Sample 1'}
[ ]:
GscMixsSoil